
系统性能量化分析-2-性能评测概述
第二讲
王磊老师主讲
评测的本质、要素、准则
评测的定位
评测为计算机系统/体系结构提供设计输入和量化依据

评测的本质
" The process of running a specific program or workload on a specific machine or system and measuring the resulting performance .” -----Saavedra, R. H., Smith, A. J.: Analysis of benchmark characteristics and benchmark performance prediction, ACM Transactions on Computer System, vol. 14, no. 4, (1996) 344-384
-
应用与系统之间的桥梁
A specific program or workload
A specific machine or system -
目标: measuring the resulting performance
评测的要素
目标系统、指标、负载/评测工具、实验分析

评测的准则
-
Apple to Apple
- 在系统层次上是对等的
- 比较的指标也是对等的
评测基准概述
- 评测的要素
目标系统、指标、负载/评测工具、实验分析
指标体系
时间 :执行时间(Wall Time)
基于时间的变形
带宽:Bandwidth
延迟:Latency
吞吐率:Throughout
加速比:Speedup
效率:Efficiency:IPC、MIPS、FLOPS
效率评价指标
-
MIPS: Million Instructions Per Second
- 优点:从指令执行的角度,衡量计算机性能
- 缺点:指令相关的指标
-
IPC: Instructions Per Cycle
- 微架构层次的指标
-
Flops : Floating-point Operations Per Second
- 64位 的浮点乘、加操作
- 测试工具:Linpack
采用主元高斯消去法求解双精度稠密线性代数方程组(AX=b),结果以每秒浮点运算次数(FLOPS)表示 - 实测峰值 & 理论峰值
- 实测峰值: FLOPS(每秒浮点运算次数) = FLOPs /Execution_time 执行时间
- 理论峰值:主频 * 每个Cycle完成Flops的理论上限次数 * 处理器核数
Intel Xeon E5645:
2.4G(主频) * 4(每个Cycle完成Flops的理论上限次数 )*6( 处理器核数) = 57.6GFLOPS
指标的作用:量化系统的手段
如何设计指标体系
整个系统的指标 & 关键模块指标
负载/评测工具

实现:不同编程语言
Benchmarks 基准的 分类、构造级别、方法、原则
评测基准的分类
微基准:Micro-benchmark
宏基准:Macro-benchmark
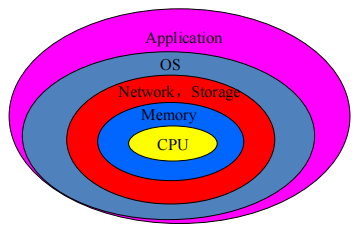
基准构建的五个层次
- Real applications
- Modified(or scripted) applications
- Kernels : linpack 不单独成应用
- Toy benchmarks
- Synthetic benchmarks: 合成基准
构造方法
-
自顶向下Top-down
representative program selection
can yield accurate representations of the program space of interest
usually impossible to make any form of hard statements about the representativeness
-
自下向上 Bottom-up
diverse range of characteristics
program characteristics are quantities that can be measured and compared
not all portions of the characteristics space are equally important
– C. Bienia. Benchmarking modern multiprocessors. PhD thesis, Princeton University, 2011.
构造原则
主要原则:==代表和覆盖==
一定要有代表性,和覆盖全面
要利于应用开发时考虑目标机器的系统结构特性,以保证系统结构的特性被充分测试
能够代表目标机器上的重要应用群
负载具有充分的多样性,能够覆盖一定的目标应用范围
程序采用最新的算法和实现技术
- benchmarks suites:基准集合
To overcome the danger of placing too many eggs in one basket, collections of benchmark applications, called benchmark suites, are a popular measure of performance of processors with a variety of applications
– Computer Architecture: A Quantitative Approach
为了克服在一个篮子中放太多鸡蛋的危险,基准应用程序的集合,称为基准套件,是衡量具有各种应用程序的处理器性能的流行方法——计算机体系结构:定量方法
评测工具举例
-
SPEC Benchmarks
Standard Performance Evaluation Corporation(标准性能评估机构)
- 涵盖众多领域
- 处理器性能评测基准程序集(SPEC CPU)
- 文件服务器评测基准(SPECSPF)
- Web服务器评测基准(SPECWeb)
- 涵盖众多领域
-
Linpack
-
应用领域:Top 500
-
Linpack Benchmarks用来度量系统的浮点计算能力
- 测试系统求解稠密线性代数方程组Ax=b的效率
- 评测指标:MFLOPS (millions of floating point operations per second)
- TOP 500排名的理论依据
-
-
PARSEC
-
应用领域:处理器
-
Princeton Application Repository for Shared- Memory Computers(PARSEC)是用于测试CMPs(Chip-Multiprocessors)的多种应用程序的集合
-
负载和工作集覆盖了很多领域
-
-
TPC Benchmarks
-
应用领域:数据库
-
数据库事务处理评测基准程序集
-
TPC-C: 评测服务器和数据库的OLTP性能
- a mid-weight read-write transaction (i.e., New-Order)
- a light-weight read-write transaction (i.e., Payment)
- a mid-weight read-only transaction (i.e., Order-Status)
- a batch of mid-weight read-write transactions (i.e., Delivery)
- a heavy-weight read-only transaction (i.e., Stock-Level)
-
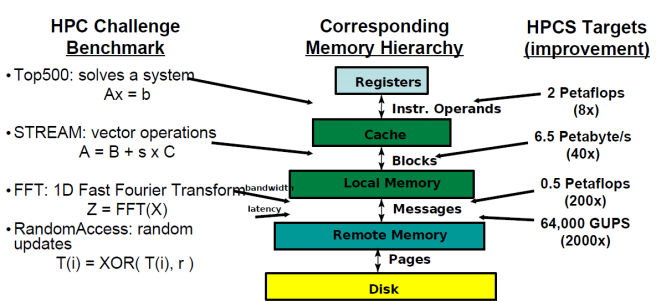
5.HPCC : HPC Challenge
- 内存访问模式 基准
- First come at 2003, widely used in 2004
HPCC 构成
1.HPL-Linpack基准,测量求解线性方程组的浮点执行率。
2.DGEMM -测量双精度实矩阵-矩阵乘法执行的浮点率。
3.流-一个简单的合成基准程序,测量可持续的内存带宽(在GB/s)和相应的计算率的简单向量核。 4.PTRANS(并行矩阵转置)-练习了成对的处理器同时进行通信的通信。这是对网络总通信能力的一个有用的测试。
5.随机访问-测量内存的整数随机更新率(GUPS)。
6.FFT -度量双精度复一维离散傅里叶变换(DFT)执行的浮点率。
7.延迟-一组测试,用于测量多个同步通信模式的延迟和带宽;基于b_eff(有效带宽基准)。
HPCC计算模式
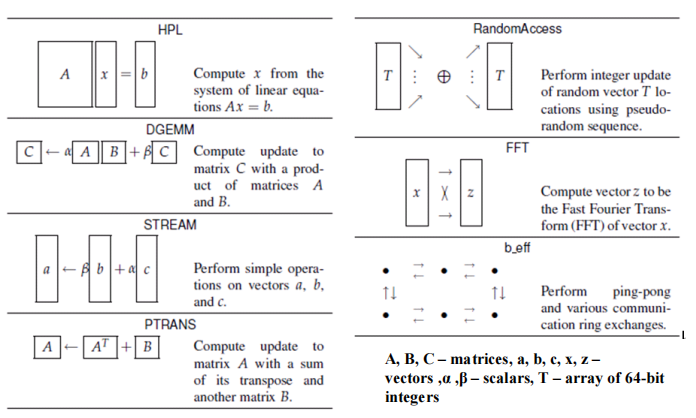
HPCC Memory Hierarchy ;内存层次结构
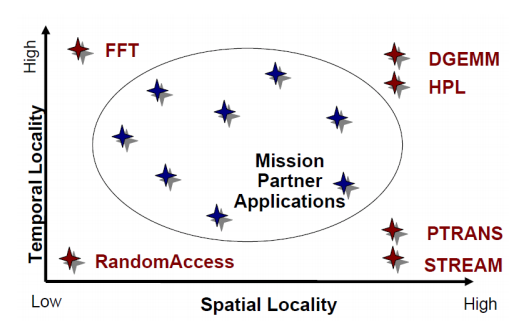
HPCC的局部性特征
空间局部性和时间局部性
实验与数据分析
统计方法、原因分析
案例
评测工具使用
性能单项评测
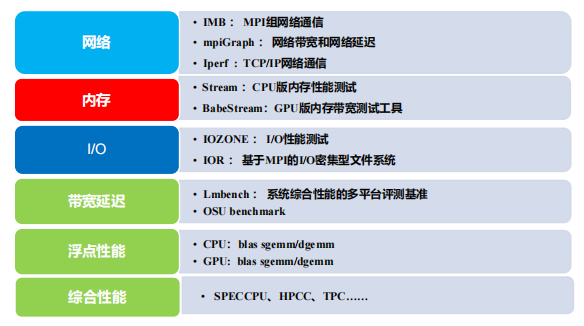
网络测试-Iperf
CPU内存测试-Stream
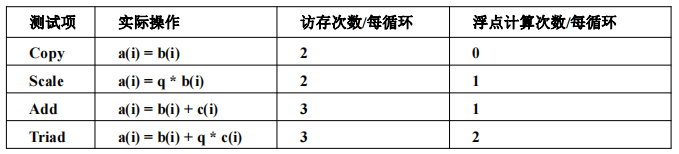
Stream为业界公认的内存带宽测试程序,通过大维度的矢量数组的处理,评价计算机系统的内存性能。
Stream主要有四种数组的运算,分别是数组的复制,数组的尺度变换,数组的矢量去和,数
组的复合矢量求和。
-
带宽技术指标
- 内存带宽理论值
Intel Xeon X5650: 1333MHz*64(总线带宽)*3(通道数)2(物理CPU数)=63.98GB
AMD Opteron 6136:1333MHz64(总线带宽)*4(通道数)*2(物理CPU数)=85.3GB - 内存带宽测试值
Intel 5650(12线程) 29.3GB =45.7%
AMD 6136(16线程) 49.0GB =57.4%
- 内存带宽理论值
-
【测试平台】
TC4600 CB60-G15
2*Intel Xeon E5-2670@2.6GHz
88GB DDR3 1600MHz**(双路节点理论带宽为16006442/8=102400 MB/s)**
-
【编译参数,其它编译优化选项没有明显效果】
icc -O3 -xHost -openmp -DN=XXX
N=XXX指定Stream数组维数
-
【运行参数,加上线程绑定测试结果稳定】
OMP_NUM_THREADS=16 KMP_AFFINITY=granularity=fine,nowarnings,compact
-
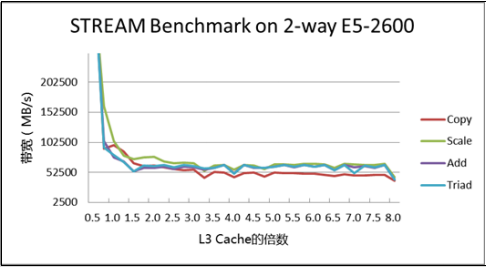
【测试结果】
考察Stream N值的影响,设置N为L3 Cache 20MB( 对应N值2010241024/8=2621440)的倍数
大数据系统的量化评测
Big Data Benchmark
大数据计算抽象
BigDataBench 概述

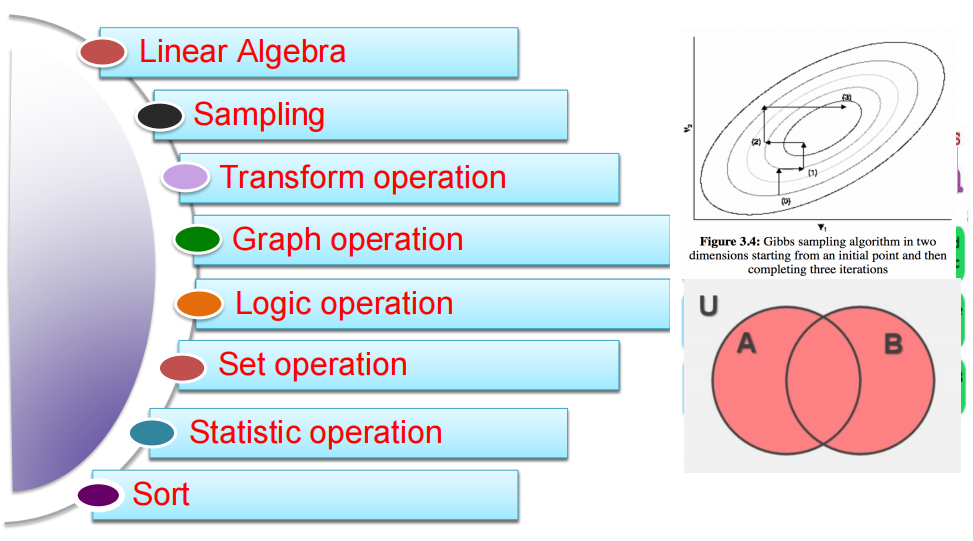
Dwarfs: 大数据计算抽象
大数据计算操作模式抽象
◼ Units of computation
◼ a minimum set to represent maximum patterns of big data analytics
开源大数据评测基准**:BigDataBench**
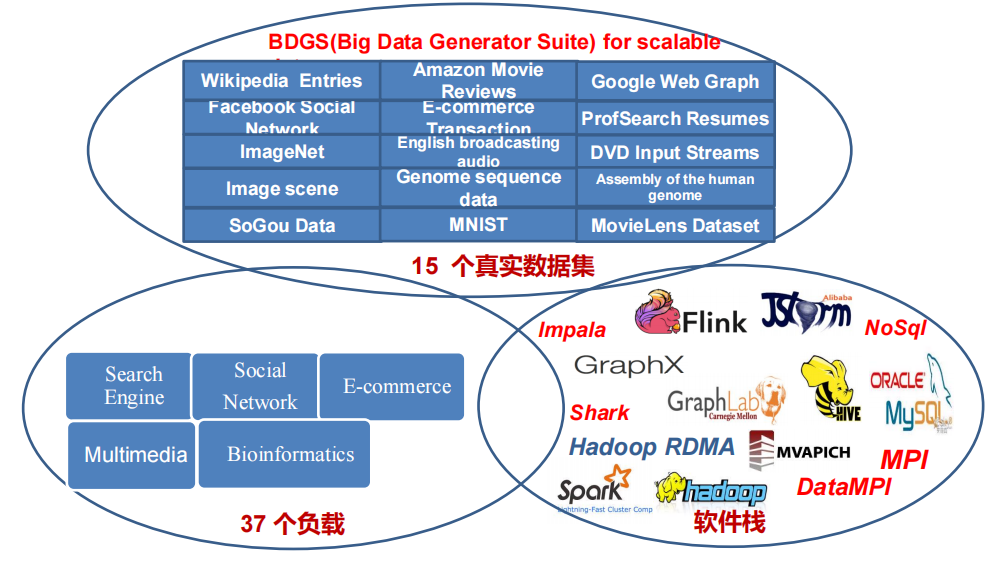
大数据负载流水线行为
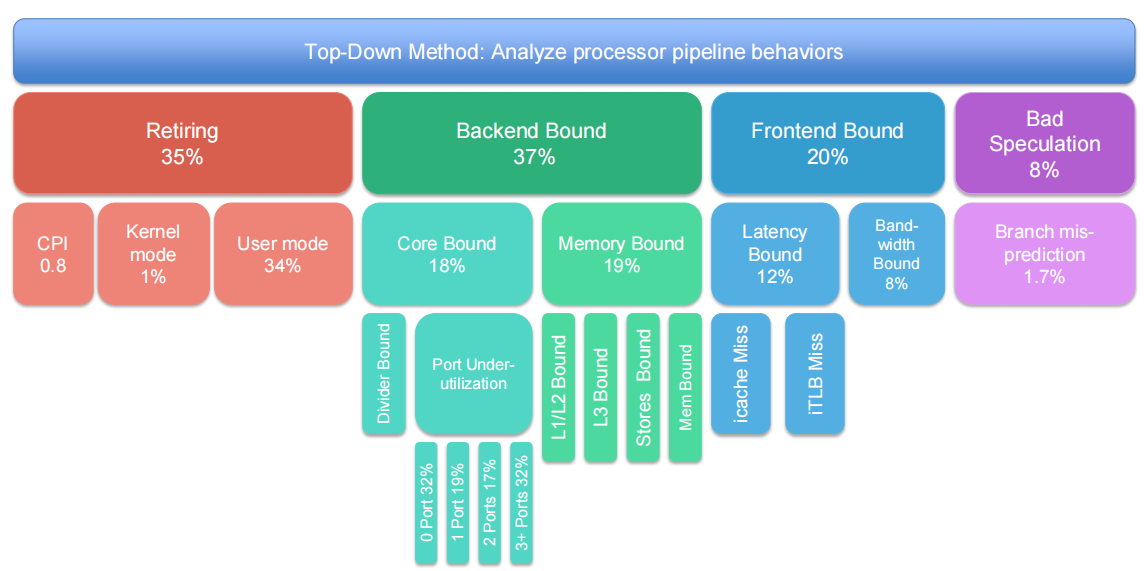
大数据体系结构负载特征
Scale-out 服务和传统Web服务(SPEC-Web, TPCC)属于同一类负载
-
数据分析负载是一类新负载
计算密度低、数据移动为主、具有更多分支指令的的计算
第一瓶颈仍是后端停顿、第二瓶颈是前端停顿
软件栈对体系结构行为有着深刻影响1. 负载生成2. 服务分解
3. 经验预测
-
用不同软件栈实现相同应用**:** L1I cache miss率有一个数量级差距
处理器优化建议
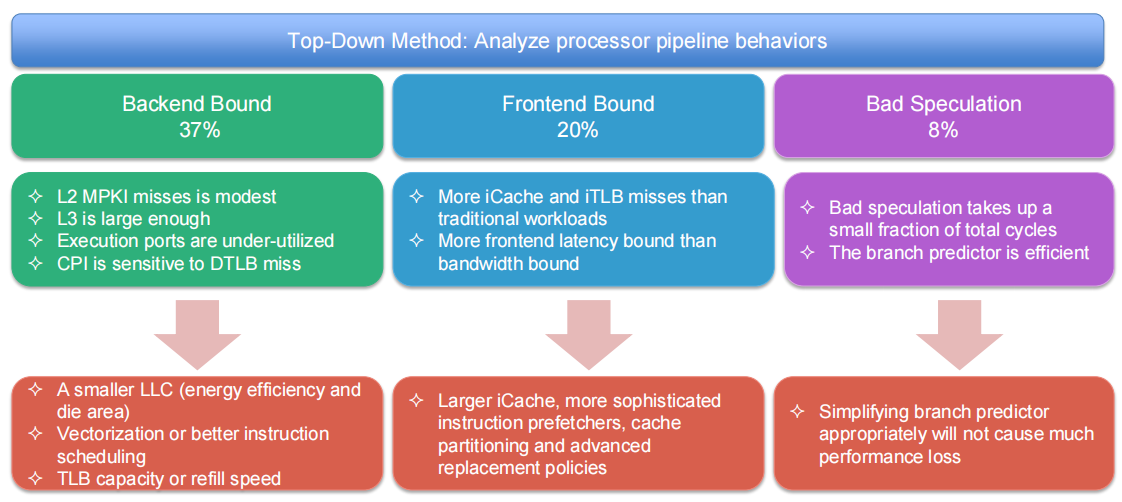
性能分析模型
-
负载生成
-
服务分解
-
经验预测
参考
 wechat
wechat alipay
alipay


