
系统性能量化分析-4-Roofline-Model
- Roofline: an insightful visual performance model for multicore architectures
Samuel Williams, Andrew Waterman, David Patterson 发表于2009年的ACM通讯,受到广泛关注 - 探索多核架构下软硬件的性能优化问题,提供理论上界
1. 问题:如何做多核系统的设计/优化
一名资深程序员日常会面临的诸多问题
下一代多核架构选择∶众多小核vs少量大核
面对已知负载,买机器是选择强算力还是高访存带宽
面对已有硬件,优化程序性能的方向和路径怎么定?

2. 基本思想:对应用和硬件进行建模分析,化繁为简
-
系统内众多组件都会对应用性能、执行时间产生影响
-
不要对架构细节进行建模,需要好的抽象
-
做一些必要且理想的假设
CPU核可以在本地数据实现峰值算力(peakGFLOP/s)
CPU核执行的是负载均衡的SPMD(数据并行)代码
片上网络的带宽充足
片上的cache容量和带宽充足
3.问题建模:抽象后的系统模型
- 抽象后的系统,应用的运行时间可以明确划分为两大块
-
数据移动时间
-
计算时间
-
应用程序到底是
- Compute-Bound
- Memory-Bound
4. 数学建模:Roofline Model 屋顶模型
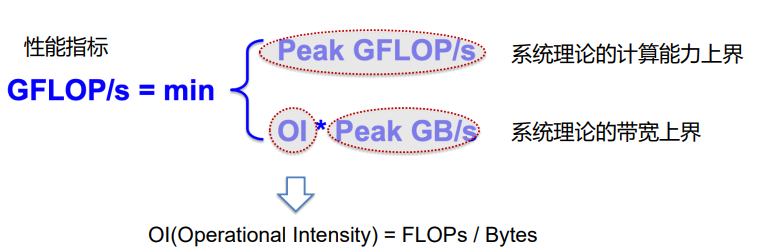
AI(Arithmetic Intensity)OI(Operational Intensity)算术密度 / 操作密度
- 内存与cache间每传输1Byte数据所包含的操作数 ,也就是操作密度
- example: 操作数/数据量bytes = AI
- 理论峰值;机器峰值(机器的带宽,硬件参数,主频、核数等等
- AI * 带宽: 内存带宽
5. 可视化分析I:Roofline Model屋顶模型
- 横坐标为操作密度
- 纵坐标为可实现的计算能力
- Log-Log坐标轴
- Roofline模型将坐标系切分成5个区域

如何应用
- 我们可以用Roofline做什么
1.分析程序性能瓶颈,启发优化方向
2.决定程序优化什么时候该停止
3.理解不同架构、编程模型、实现等等之间的性能差异点
4.预测未来架构设计方向 - 进一步思考
- 在具体实践过程中,该如何采集相关参数
- 描述能力很强,还可以泛化到哪些领域
1、利用Roofline Model做硬件对比
TPU、GPU和CPU的Roofline对比
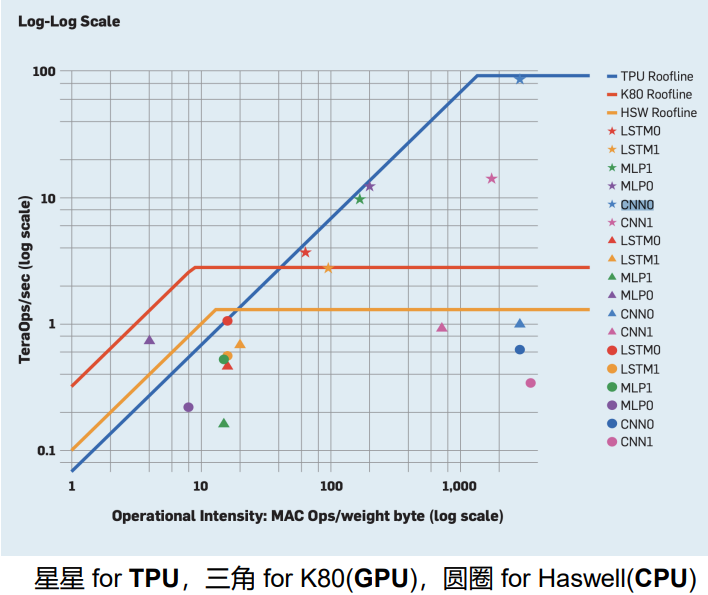
-
TPU的峰值算力最强,
MLP和 LSTM 是 memory-bound ,
CNN是compute-bound -
6个应用离GPU和CPU的顶都比较远
2、Roofline Model 的HPC负载应用:
概述

3、使用Roofline Model评估典型大数据负载
负载特征
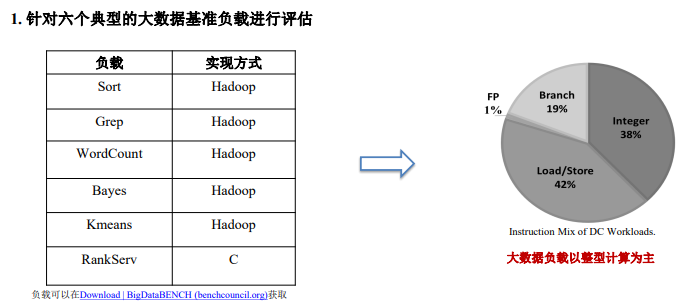
评估结果

Roofline Model 对于大数据负载失效 !! 原因是什么?如何改进?
改进模型:DC-Roofline

DC-Roofline可以反映大数据负载的性能 Roofline无法反映大数据负载的性能
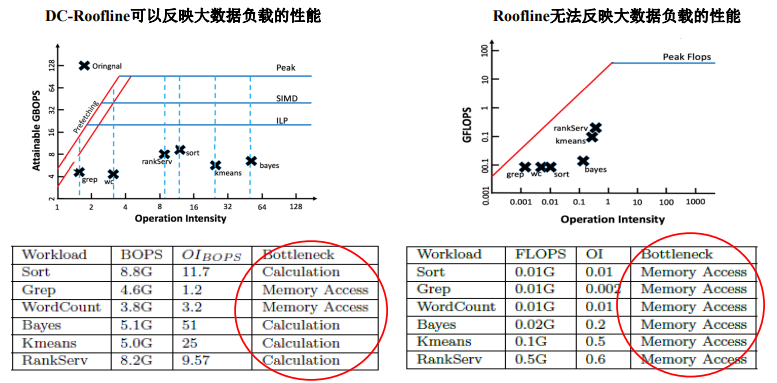
DC-Roofline优化大数据负载
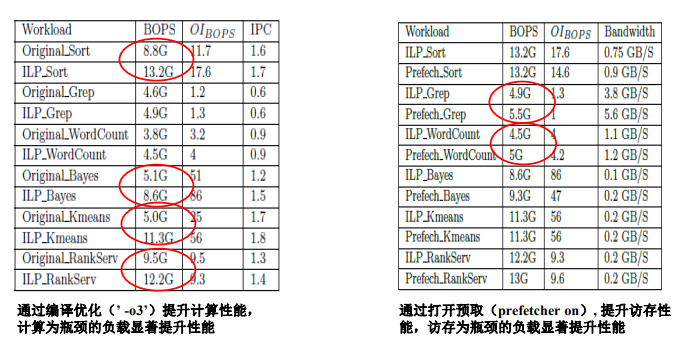
DC-Roofline优化效果总结
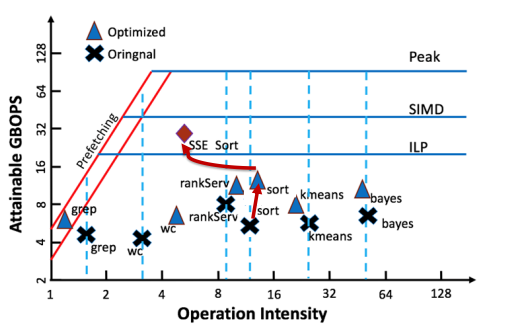
总结Roofline Model 应用思路
- 构建计算公式:确定性能目标(根据负载特征)
- 获取变量数值:利用处理器的性能计数器(PMU〉使用Linux Perf工具获取
- 绘制可视化视图:确定优化路径
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 JLChenBlog!
 wechat
wechat alipay
alipay
相关推荐


评论