
读《深度学习推荐系统》——王喆
书名:深度学习推荐系统
作者:王喆
出版社:电子工业出版社
出版时间:2020-03-01
ISBN:9787121384646
- 本篇为笔者阅读该书简要总结,推荐阅读原书。
- 传统推荐模型烟花关系图
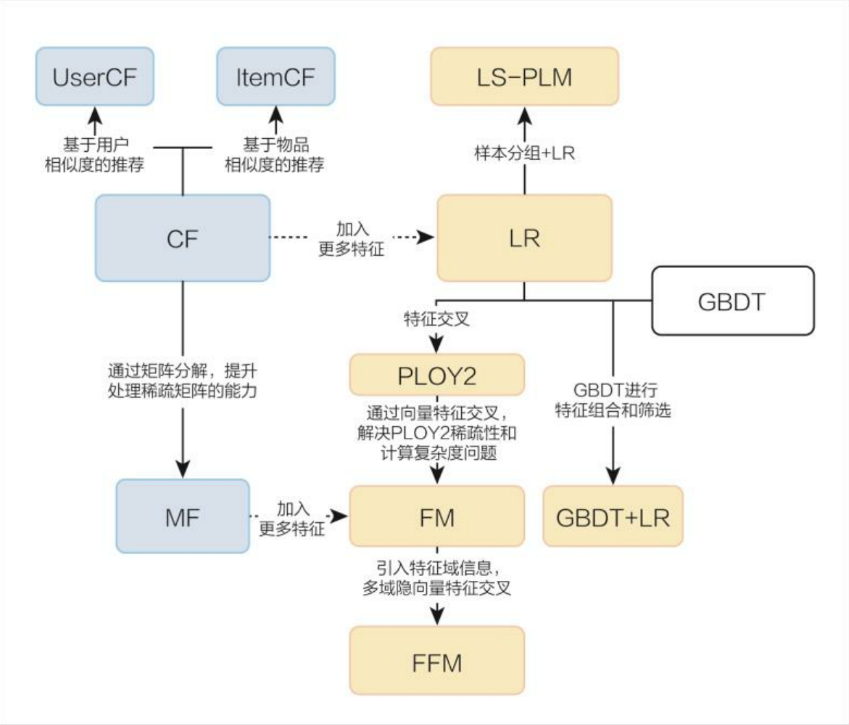
| 协同过滤算法族 | 从物品相似度和用户相似度角度出发,协同过滤衍生出物品协同过滤(ItemCF)和用户协同过滤(UserCF)两种算法,再到MF | |
| 逻辑回归算法族 | 与协同过滤仅利用用户和物品之间的显式或隐式反馈信息相比,逻辑回归能够利用和融合更多用户、物品及上下文特征 | |
| 因子分解机模型族 | 因子分解机在传统逻辑回归的基础上,加入了二阶部分,使模型具备了进行特征组合的能力 | |
| 组合模型 | 组合模型中体现出的特征工程模型化的思想,也成了深度学习推荐模型的引子和核心思想之一 |
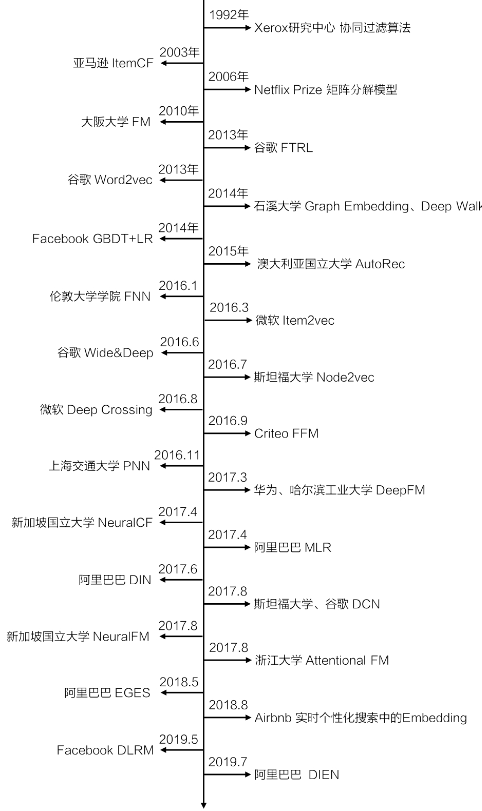
- 主流深度学习推荐模型演化图谱
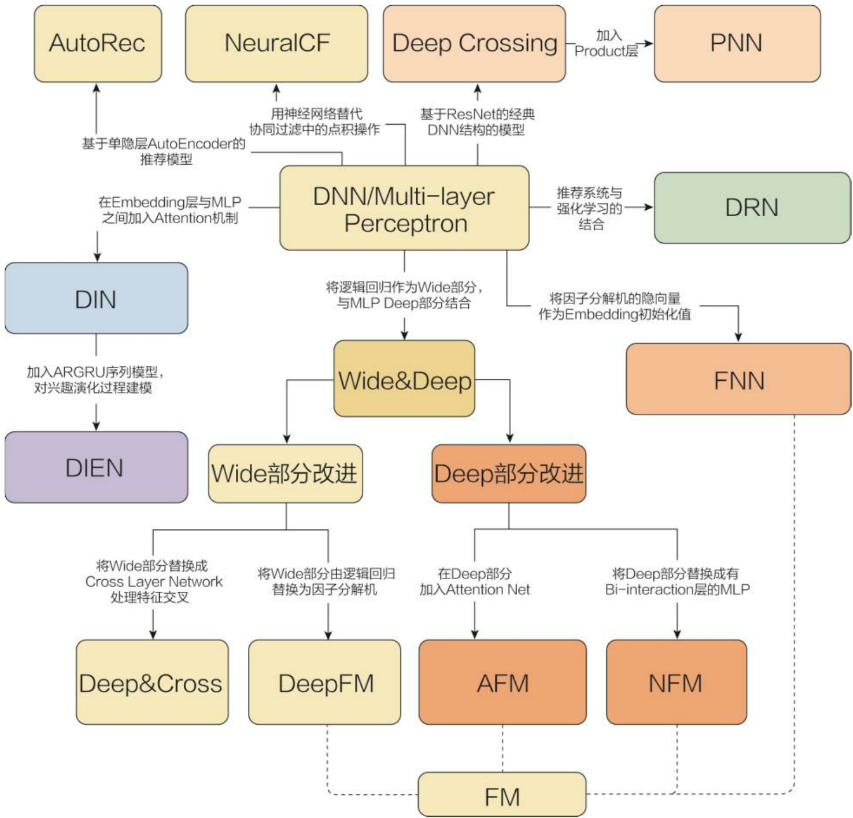
- 主要演变方向
| 改变NN的复杂度 | ||
| 改变特征交叉方式 | ||
| 组合模型 | ||
| FM模型的深度学习演化版本 | ||
| 注意力机制+rec | ||
| 序列模型+rec | ||
| 强化学习+rec |
文中形式化定义推荐系统
-
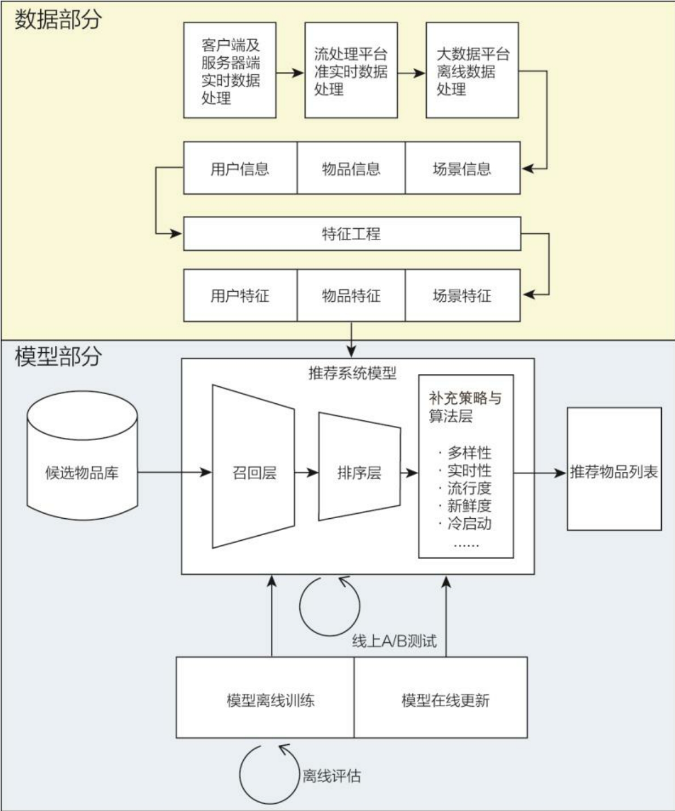
推荐系统的逻辑架构
对于用户U(user),在特定场景C(context)下,针对海量的“物品”信息,构建一个函数f(U,I,C),预测用户对特定候选物品I(item)的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题。
-
推荐系统的技术架构
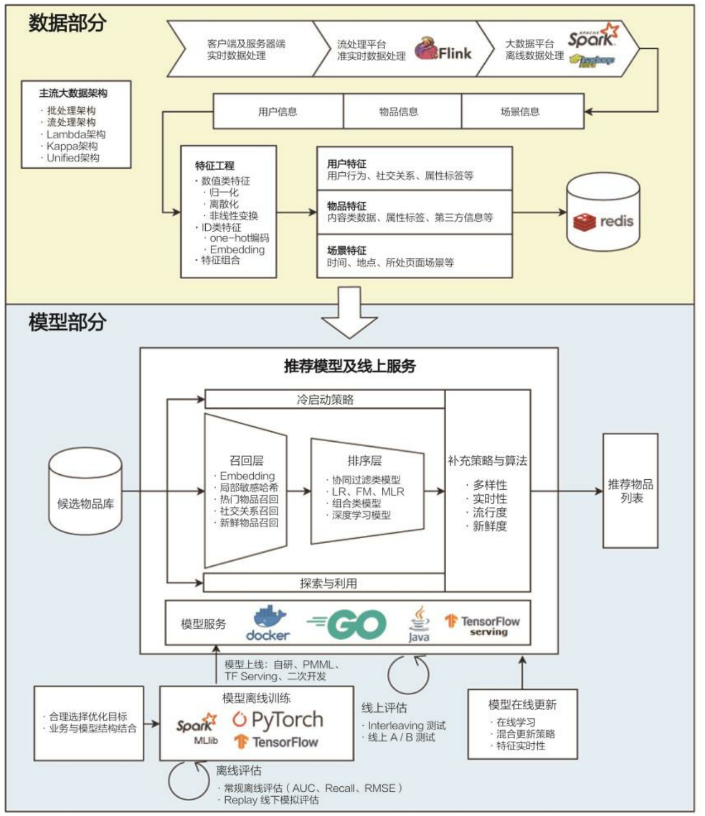
推荐系统实现,工程化;技术架构示意图如下- 数据和信息相关问题
- 即“用户信息”“物品信息”“场景信息”分别是什么?如何存储、更新和处理
- 逐渐发展为推荐系统中融合了数据离线批处理、实时流处理的数据流框架
- 推荐系统算法和模型相关问题
- 即推荐模型如何训练、如何预测、如何达成更好的推荐效果?
- “算法和模型”部分则进一步细化为推荐系统中集训练(training)、评估(evaluation)、部署(deployment)、线上推断(online inference)为一体的模型框架
- 数据和信息相关问题
特征工程自动化道路
-
GBDT+LR组合模型的提出,意味着特征工程可以完全交由一个独立的模型来完成,模型的输入可以是原始的特征向量,不必在特征工程上投入过多的人工筛选和模型设计的精力,实现真正的端到端(End to End)训练
深度学习模型通过各类网络结构、Embedding层等方法完成特征工程的自动化,都是GBDT+LR开启的特征工程模型化这一趋势的延续。 -
从目前的时间节点上看,Deep Crossing模型是平淡无奇的,因为它没有引入任何诸如注意力机制、序列模型等特殊的模型结构,只是采用了常规的“Embedding+多层神经网络”的经典深度学习结构。但从历史的尺度看,Deep Crossing模型的出现是有革命意义的。Deep Crossing模型中没有任何人工特征工程的参与,原始特征经Embedding后输入神经网络层,将全部特征交叉的任务交给模型。相比之前介绍的FM、FFM模型只具备二阶特征交叉的能力,Deep Crossing模型可以通过调整神经网络的深度进行特征之间的“深度交叉”,这也是Deep Crossing名称的由来
| 年份 | 模型 | 主要思想 | 优点 | 缺点 | |
|---|---|---|---|---|---|
| 2014 | GBDT+LR | GBDT+LR组合模型的提出,意味着特征工程可以完全交由一个独立的模型来完成,模型的输入可以是原始的特征向量,不必在特征工程上投入过多的人工筛选和模型设计的精力,实现真正的端到端(End to End)训练 | |||
| 2015 | AutoRec | 单隐藏层NN 推荐 | |||
| 2016 | Deep Crossing | ResNet做特征交叉 | 相比AutoRec模型过于简单的网络结构带来的一些表达能力不强的问题,Deep Crossing模型完整地解决了从特征工程、稀疏向量稠密化、多层神经网络进行优化目标拟合等一系列深度学习在推荐系统中的应用问题,为后续的研究打下了良好的基础。 | ||
| 2017 | NeuralCF | MLPS+softmax输出层替代, (U ,I之间的互操作形式) |
以上仅包括交互信息 | ||
| 2016 | PNN | 引入product Layer | 加入用户、物品之外的特征向量 | 外积操作中的简化操作 对所有特征无差别交叉 |
|
| 20161 | Wide&Deep | Wide部分的主要作用是让模型具有较强的“记忆能力”(memorization); Deep部分的主要作用是让模型具有“泛化能力”(generalization) |
不仅综合了“记忆能力”和“泛化能力”,而且开启了不同网络结构融合的新思路 | ||
| 2017 | Deep&Cross (DCN) |
使用Cross网络替代原来的Wide部分, 增加特征之间的交互力度 使用多层交叉层(Cross layer)对输入向量进行特征交叉 |
由多层交叉层组成的Cross 网络在Wide&Deep模型中Wide部分的基础上进行特征的自动化交叉,避免了更多基于业务理解的人工特征组合 | DeepFM、NFM等模型都可以看成Wide&Deep模型的延伸。 | |
| 2017 | DeepFM | 用FM代替Wide部分 | |||
FM路线
在神经网络的参数初始化过程中,往往采用随机初始化这种不包含任何先验信息的初始化方法。由于Embedding层的输入极端稀疏化,导致Embedding层的收敛速度非常缓慢。再加上Embedding层的参数数量往往占整个神经网络参数数量的大半以上,因此***模型的收敛速度往往受限于Embedding层***
| 缺点 | ||||
|---|---|---|---|---|
| POLY2 | ||||
| 2010 | FM | 与POLY2相比,其主要区别是用两个向量的内积取代了单一的权重系数w | FM为每个特征学习了一个隐权重向量(latent vector)。在特征交叉时,使用两个特征隐向量的内积作为交叉特征的权重 FM 是将矩阵分解隐向量的思想进行了进一步扩展,从单纯的用户、物品隐向量扩展到了所有特征上。 |
|
| 2015 | FFM | 相比FM模型,FFM模型引入了特征域感知(field-aware)这一概念,使模型的表达能力更强 | 是一个二阶特征交叉的模型。受组合爆炸问题的困扰,FM 几乎不可能扩展到三阶以上,这就不可避免地限制了FM模型的表达能力 | |
| 2016 | FNN | 类似于Deep Crossing,改进Embedding层 用FM模型训练好的各特征隐向量初始化Embedding 层的参数 也为另一种Embedding 层的处理方式——Embedding 预训练提供了借鉴思路 |
并没有对神经网络的结构进行调整 | |
| 2017 | DeepFM | 用FM代替Wide部分 | ||
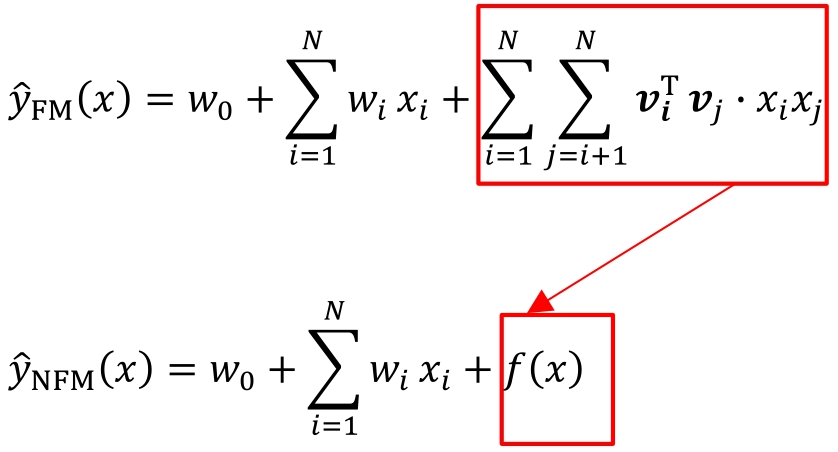
| 2017 | NFM | 在数学形式上,NFM模型的主要思路是用一个表达能力更强的函数替代原FM中二阶隐向量内积的部分 | 使用神经网络代替FM中二阶交叉部分 NN中包括特征交叉池化层 如果把NFM的一阶部分视为一个线性模型,那么NFM的架构也可以视为Wide&Deep模型的进化。相比原始的Wide&Deep模型,NFM模型对其Deep 部分加入了特征交叉池化层,加强了特征交叉。这是理解NFM模型的另一个角度 |
加和池化(Sum Pooling)操作,它相当于“一视同仁”地对待所有交叉特征,不考虑不同特征对结果的影响程度,事实上消解了大量有价值的信息 |
| 2017 | AFM | |||
Wide&Deep
Wide&Deep模型把单输入层的Wide部分与由Embedding层和多隐层组成的Deep部分连接起来,一起输入最终的输出层。单层的Wide部分善于处理大量稀疏的id类特征;Deep部分利用神经网络表达能力强的特点,进行深层的特征交叉,挖掘藏在特征背后的数据模式。最终,利用逻辑回归模型,输出层将Wide部分和Deep部分组合起来,形成统一的模型
Wide&Deep模型的详细结构
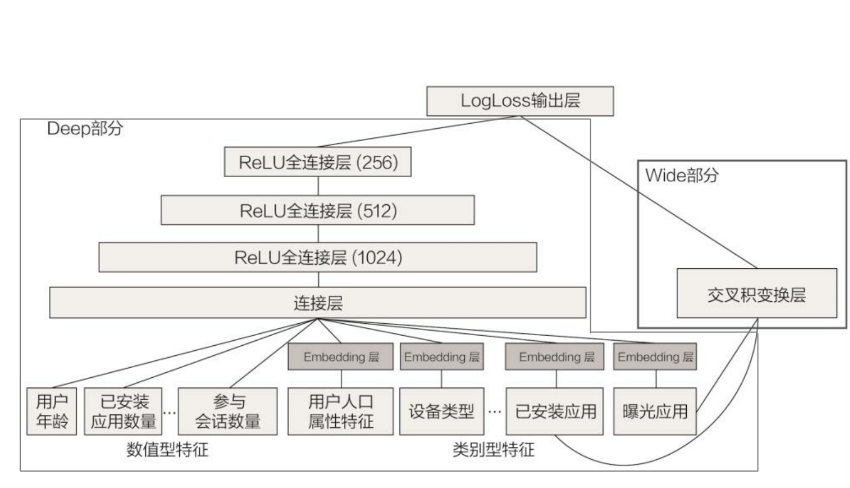
其他技术路线
注意力机制
| 2017 | AFM | NFM模型的延续; 加和池化(Sum Pooling)操作,它相当于“一视同仁”地对待所有交叉特征,不考虑不同特征对结果的影响程度,事实上消解了大量有价值的信息 AFM模型引入注意力机制是通过在特征交叉层和最终的输出层之间加入注意力网络(Attention Net)实现的,生成注意力得分 |
该注意力网络的结构是一个简单的单全连接层加softmax输出层的结构 | |
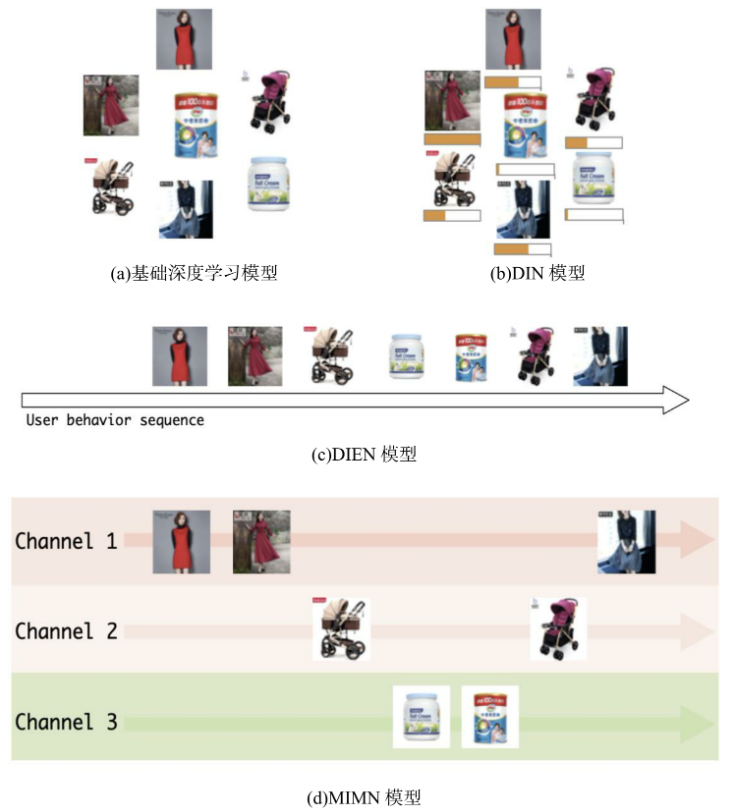
| 2018 | DIN | 在原来的基础模型中(图3-24中的Base模型),用户特征组中的商品序列和商铺序列经过简单的平均池化操作后就进入上层神经网络进行下一步训练,序列中的商品既没有区分重要程度,也和广告特征中的商品id没有关系 |
||
| 注意力机制在数学形式上只是将过去的平均操作或加和操作换成了加权和或者加权平均操作 | ||||
| 从“注意力机制”开始,越来越多对深度学习模型结构的改进是基于对用户行为的深刻观察而得出的 | ||||
序列模型
在工程实现上需要注意:序列模型比较高的训练复杂度,以及在线上推断过程中的串行推断,使其在模型服务过程中延迟较大,这无疑增大了其上线的难度,需要在工程上着重优化
| 2019 | DIEN | 创新点在于如何构建“兴趣进化网络 | 应用场景同DIN | |
强化学习+Rec
| 2018 | DRN | |||
Embedding
| Embedding | ||||||
| 2013 | 谷歌 | Word2vec | Word2vec的两种模型结构CBOW和Skip-gram | |||
| 2016 | 微软 | Item2Vec | Item2vec与Word2vec唯一的不同在于,Item2vec摒弃了时间窗口的概念,认为序列中任意两个物品都相关,因此在Item2vec的目标函数中可以看到,其是两两物品的对数概率的和,而不仅是时间窗口内物品的对数概率之和 | Item2vec方法也有其局限性,因为只能利用序列型数据,所以Item2vec在处理互联网场景下大量的网络化数据时往往显得捉襟见肘,这就是Graph Embedding技术出现的动因 | ||
| 广义Itemsvec 双塔模型 |
广义上的Item2vec模型其实是物品向量化方法的统称 | Word2vec和由其衍生出的Item2vec是Embedding技术的基础性方法,但二者都是建立在“序列”样本(比如句子、用户行为序列)的基础上的 | ||||
| Graph Embedding | Graph Embedding是一种对图结构中的节点进行Embedding编码的方法。最终生成的节点Embedding 向量一般包含图的结构信息及附近节点的局部相似性信息 | |||||
| 2014 | 阿里 | DeepWalk | 在由物品组成的图结构上进行随机游走,产生大量物品序列,作为训练样本输入Word2vec 进行训练,得到物品的Embedding。 | DeepWalk可以被看作连接序列Embedding和Graph Embedding的过渡方法 | ||
| 2016 | 斯坦福 | Node2vec | 通过调整随机游走权重的方法使Graph Embedding的结果更倾向于体现网络的同质性(homophily)或结构性(structural equivalence) | Node2vec算法中,是怎样控制BFS和DFS的倾向性的呢?主要是通过节点间的跳转概率 | ||
| 2018 | 阿里巴巴 | EGES | 在淘宝应用的Embedding方法EGES(Enhanced Graph Embedding with Side Information), 基本思想是在DeepWalk生成的Graph Embedding基础上引入补充信息。 注意力权重embedding加权求和 |
物品冷启动问题,通过引入更多补充信息(side information)来丰富Embedding信息的来源,从而使没有历史行为记录的商品获得较合理的初始Embedding | ||
| LINE | ||||||
| SDNE |
Embedding与深度学习推荐系统的结合
(1)在深度学习网络中作为Embedding层,完成从高维稀疏特征向量到低维稠密特征向量的转换。
(2)作为预训练的Embedding特征向量,与其他特征向量连接后,一同输入深度学习网络进行训练。
(3)通过计算用户和物品的Embedding相似度,Embedding可以直接作为推荐系统的召回层或者召回策略之一。
1, 作为Embedding层
embedding 层与整个深度学习网络整合后一同进行训练是理论上最优的选择,因为上层梯度可以直接反向传播到输入层,模型整体是自洽的。但这样做的缺点是显而易见的,Embedding 层输入向量的维度往往很大,导致整个Embedding层的参数数量巨大,因此Embedding层的加入会拖慢整个神经网络的收敛速度(3.7节的基础知识中曾详细论证过这一点)
很多工程上要求快速更新的深度学习推荐系统放弃了Embedding层的端到端训练,用预训练Embedding层的方式替代。
2,Embedding作为推荐系统召回层
局部敏感哈希
-
传统的Embedding相似度的计算方法是Embedding向量间的内积运算,这就意味着为了筛选某个用户的候选物品,需要对候选集合中的所有物品进行遍历。在k维的Embedding空间中,物品总数为n,那么遍历计算用户和物品向量相似度的时间复杂度是O(kn)
-
通过建立kd(k-dimension)树索引结构进行最近邻搜索是常用的快速最近邻搜索方法,时间复杂度可以降低到O(log2n)。一方面,kd树的结构较复杂,而且在进行最近邻搜索时往往还要进行回溯,确保最近邻的结果,导致搜索过程较复杂;另一方面,O(log2n)的时间复杂度并不是完全理想的状
-
推荐系统工程实践上主流的快速Embedding 向量最近邻搜索方法——局部敏感哈希(Locality Sensitive Hashing,LSH)[12]。
局部敏感哈希的基本思想是让相邻的点落入同一个“桶”,这样在进行最近邻搜索时,仅需要在一个桶内,或相邻的几个桶内的元素中进行搜索即可。如果保持每个桶中的元素个数在一个常数附近,就可以把最近邻搜索的时间复杂度降低到常数级别
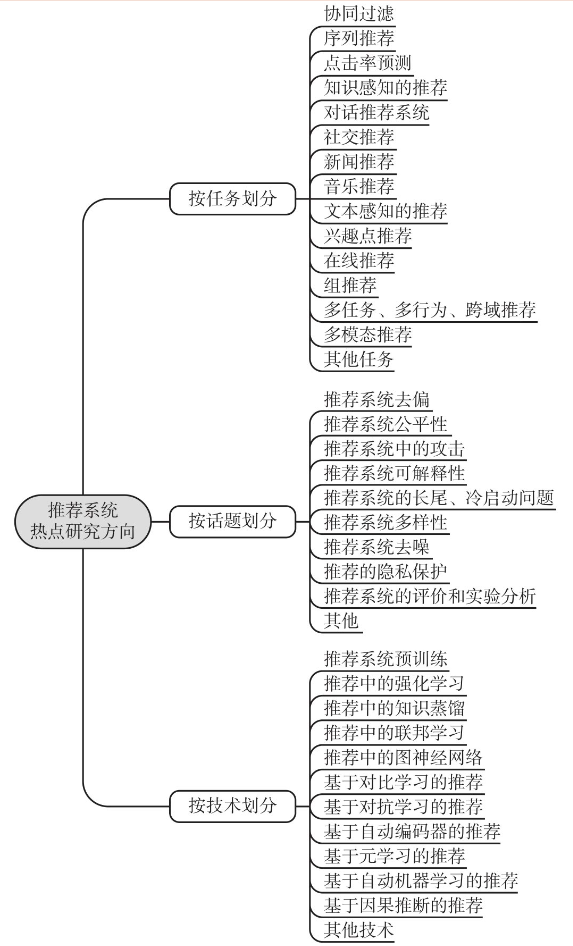
多角度审视推荐系统
推荐模型只是推荐系统的一部分,除此之外,还有很多考虑的问题
(1)推荐系统如何选取和处理特征?
(2)推荐系统召回层的主要策略有哪些?
(3)推荐系统实时性的重要性体现在哪儿?有哪些提高实时性的方法?
(4)如何根据具体场景构建推荐模型的优化目标?
(5)如何基于用户动机改进模型结构?
(6)推荐系统冷启动问题的解决方法有哪些?
(7)什么是“探索与利用”问题?有哪些主流的解决方法?
还有
可解释性
| perspective | 常用的 | ||||
|---|---|---|---|---|---|
| 特征工程 | 从具体的行为转化成抽象的特征 | 信息损失,(有用或者冗余的) 无法手机或存储;过拟合 |
置身处地 | 特征工程与模型结构统一思考、整体建模的深度学习模式 | |
| 召回 | 设计召回层时,“计算速度”和“召回率”其实是矛盾的两个指标 | 多路召回(业务强相关) 基于Embedding召回 |
多路召回中使用“兴趣标签”“热门度”“流行趋势”“物品属性”等信息都可以作为Embedding召回方法中的附加信息(side information)融合进最终的Embedding向量中 | 多路召回中使用“兴趣标签”“热门度”“流行趋势”“物品属性”等信息都可以作为Embedding召回方法中的附加信息(side information)融合进最终的Embedding向量中 | |
| 实时性 | 推荐系统特征的实时性指的是“实时”地收集和更新推荐模型的输入特征,使推荐系统总能使用最新的特征进行预测和推荐 各种实时数据处理架构 |
模型的实时性则是希望更快地抓住全局层面的新数据模式,发现新的趋势和相关性 模型的实时性由弱到强的训练方式分别是全量更新、增量更新和在线学习(Online Learning) |
|||
| 系统优化目标 | YouTube以观看时长为优化目标 | 为了达到同时优化CTR和CVR模型的目的,阿里巴巴提出了多目标优化模型ESMM(Entire Space Multi-task Model)[4]。ESMM可以被当作一个同时模拟“曝光到点击”和“点击到转化”两个阶段的模型。 | 优化目标”这个话题,笔者想强调的第三点不是技术型问题,而是团队合作的问题 | ||
| 从用户的角度思考问题 | 相比这些技术原因, | 在构建推荐模型的过程中,从应用场景出发,基于用户行为和数据的特点,提出合理的改进模型的动机才是最重要的。 | |||
| 冷启动 | “探索与利用”机制 | ||||
| 探索与利用 | 探索与利用思想是所有推荐系统不可或缺的补充。相比推荐模型的优化目标——利用已有数据做到现有条件下的利益最大化,探索与利用的思想实际上是着眼于未来的,着眼于用户的长期兴趣和公司的长期利益 | ||||
推荐系统的工程实现
| 数据流 | ||||
| 训练 | ||||
| 部署 | ||||
推荐系统评估
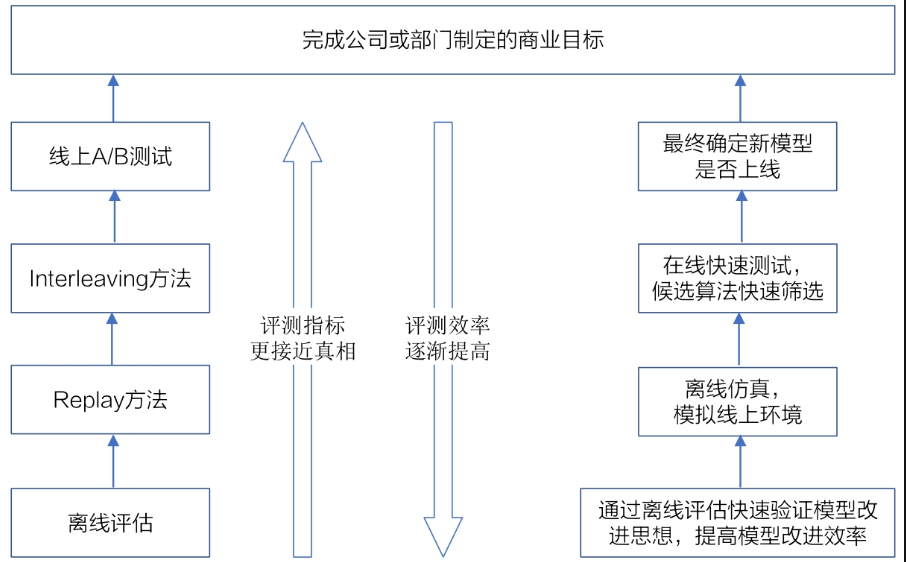
一般离线评估方法
| 点击率预估评估 | 推荐序列评估 | |||
|---|---|---|---|---|
| P | P-R | P-R 曲线的横轴是召回率,纵轴是精确率 | 同P-R 曲线一样,ROC 曲线也是通过不断移动模型正样本阈值生成的 | |
| R | 精确率(Precision)是分类正确的正样本个数占分类器判定为正样本的样本个数的比例,召回率(Recall)是分类正确的正样本个数占真正的正样本个数的比例 | P-R AUC |
AUC 指的是P-R 曲线下的面积大小,因此计算AUC值只需要沿着P-R曲线横轴做积分。AUC越大,排序模型的性能越好 | |
| F1 | 采用Top N排序结果的精确率(Precision@N)和召回率(Recall@N)来衡量排序模型的性能,即认为模型排序的To p N的结果就是模型判定的正样本,然后计算Precision@N和Recall@N | ROC | ROC曲线的横坐标为False Positive Rate(FPR,假阳性率);纵坐标为True Positive Rate(TPR,真阳性率 | ROC 的纵坐标就是召回率; |
| RMSE | 均方根误差 | ROC AUC |
同P-R曲线一样,可以计算出ROC曲线的AUC,并用AUC评估推荐系统排序模型的优劣 | |
| MAPE | 相比RMSE,MAPE相当于把每个点的误差进行了归一化,降低了个别离群点带来的绝对误差的影响 | AP | AP的计算只取正样本处的precision进行平均 | |
| LogLoss | LogLoss就是逻辑回归的损失函数 | mAP | 平均精度均值(mean Average Precision,mAP): 是对平均精度(Average Precision,AP)的再次平均 | 推荐系统对测试集中的每个用户都进行样本排序,那么每个用户都会计算出一个AP值,再对所有用户的AP值进行平均,就得到了mAP |
| NDCG | ||||
| Hit | ||||
| 覆盖率 | ||||
| 多样性 | ||||
离线评估的目的在于快速定位问题,快速排除不可行的思路,为线上评估找到“靠谱”的候选者
更接近线上环境的离线评估方法——Replay
- 动态离线评估方法先根据样本产生时间对测试样本由早到晚进行排序,再用模型根据样本时间依次进行预测。在模型更新的时间点上,模型需要增量学习更新时间点前的测试样本,更新后继续进行后续的评估
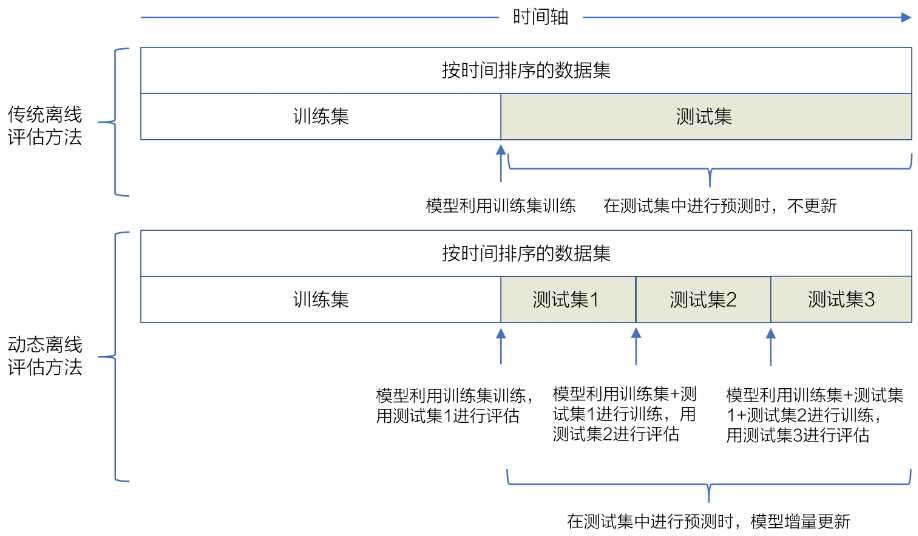
A/B测试
A/B 测试又称为“分流测试”或“分桶测试”,是一个随机实验,通常被分为实验组和对照组。在利用控制变量法保持单一变量的前提下,将A、B两组数据进行对比,得出实验结
-
谷歌关于其实验平台的论文Overlapping Experiment Infrastructure:More,Better,Faster Experimentation[2]详细地介绍了实验流量分层和分流的机制,它保证了宝贵的线上测试流量的高可用性。
-
A/B测试分层和分流的机制
(1)层与层之间的流量“正交”。
层与层之间的流量“正交”的具体含义为:层与层之间的独立实验的流量是正交的,即实验中每组的流量穿越该层后,都会被再次随机打散,且均匀地分布在下层实验的每个实验组中(2)同层之间的流量“互斥”
-
线上A/B测试的评估指标
快速线上评估方法——Interleaving
2013
矛盾——算法工程师日益增长的A/B测试需求和线上A/B测试资源严重不足之间的矛盾。
-
这种不区分A/B组,而是把不同的被测对象同时提供给受试者,最后根据受试者喜好得出评估结果的方法就是Interleaving方法。
而在Interleaving 方法中,只有一组订阅用户,这些订阅用户会收到通过混合算法A和B的排名生成的交替排名。这就使得用户可以在一行里同时看到算法A 和B的推荐结果(用户无法区分一个物品是由算法A推荐的还是由算法B推荐的),进而通过计算观看时长等指标来衡量到底是算法A的效果好还是算法B的效果好
深度学习推荐系统——前沿实践
| 2014 | GBDT+LR | |||
| 2019 | DLRM(Deep Learning Recommender Model) | DLRM 融合使用了模型并行和数据并行的方法Embedding部分采用模型并行, MLP 部分采用数据并行 | ||
| 2017 | DCN | |||
| Airbnb | ||||
| 2018 | Real-time Personalization using Embeddings for Search Ranking at Airbnb(KDD2018 best paper) | session内短期兴趣embedding,和长期兴趣embedding | ||
| YouTube | ||||
| 2016 | Deep Neural Networks for YouTube Recommenders | 召回+排序 | ||
| 阿里巴巴 | ||||
| 2017 | LS-PLM | |||
| 2018 | DIN | 利用注意力机制替换基础模型的Sum Pooling操作,根据候选广告和用户历史行为之间的关系确定每个历史行为的权重 | 基于经典的Embedding+MLP 深度学习模型架构,将用户行为历史的Embedding简单地通过加和池化操作叠加,再与其他用户特征、广告特征、场景特征连接后输入上层神经网络进行训练 | |
| 2018 | 多目标优化模型ESMM(Entire Space Multi-task Model) | |||
| 2019.7 | DIEN | 在DIN的基础上,进一步改进对用户行为历史的建模,使用序列模型在用户行为历史之上抽取用户兴趣并模拟用户兴趣的演化过程 | ||
| 2019 | Multi-channel user Interest Memory Network,MIMN | 在DIEN的基础上,将用户的兴趣细分为不同兴趣通道,进一步模拟用户在不同兴趣通道上的演化过程,生成不同兴趣通道的记忆向量,再利用注意力机制作用于多层神经网络 |
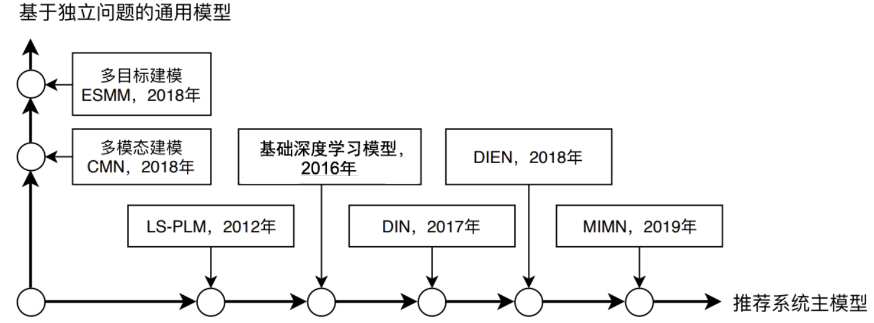
推荐系统知识框架
- 《图计算与推荐系统》——刘宇
reference
- 《深度学习推荐系统》——王喆
 wechat
wechat alipay
alipay
