
推荐系统简述
推荐系统
什么是推荐
- 推荐是一种思维方式
- 作为搜索的延申
- 作为广告的土壤
- 掌握信息传播主动权
- 适用场景
- 资源受限的信息过滤
- 导向性的信息展现
- 目的性的资源分配
解决问题
-
信息过载
-
挖掘长尾
- 长尾
是指那些原来不受到重视的销量小但种类多的产品或服务由于总量巨大,累积起来的总收益超过主流产品的现象。在互联网领域,长尾效应尤为显著。长尾术语也在统计学中被使用,通常应用在财产的分布和词汇。 - 帕雷托法则
向来被商业界视为铁律,其内涵认为企业界80%的业绩来自20%的产品
数据、物品价值
- 长尾
-
用户体验
提升用户体验;帮助用户发现自己很难发现的兴趣点、商品……
推荐系统的技术演进
早期论坛的打分系统;hacknews;reddit;
早期社交内容
早期电商内容
单一算法到多算法融合
基于内容的算法 ;( 文本相关性, 主题相关性)
基于行为的算法 ;( 协同过滤的变种,随机游走等其他行为类算法 )
结果融合;人工规则引入机器学习模型
启发式,无明确目标
相对静态,反应慢
考虑维度较少,个性化程度不足
纯手工,改进空间小对齐明确目标,成熟的优化方法
时效性灵活,反映可快可慢特征维度丰富,个性化程度细腻
理论储备丰富,发展空间大深度学习
- 从浅层模型到深度模型

推荐系统基本流程
-
召回
- 协同过滤
- 内容相似召回
- 热门召回
- ……
-
排序
- 机器学习
- 二分类算法
- 深度学习算法
-
调整(重排)
- 针对 具体场景
- 去重
- 过滤,热门补充
召回
-
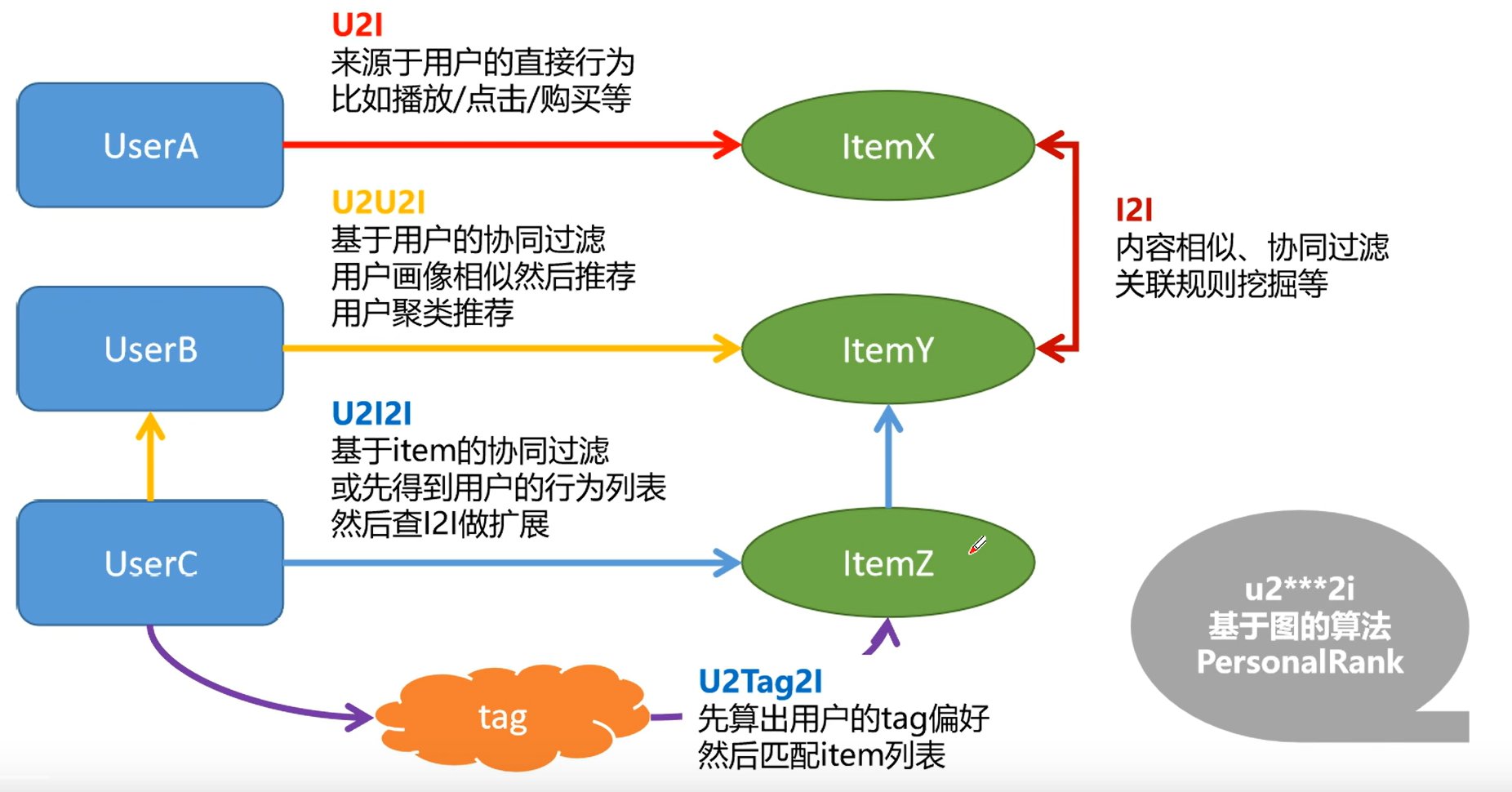
一般召回路径
- i2i
- u2i
- u2i2i
- u2u2i
- u2tag2i
泛化性好 - u2***2i
基于图的算法
排序
调整
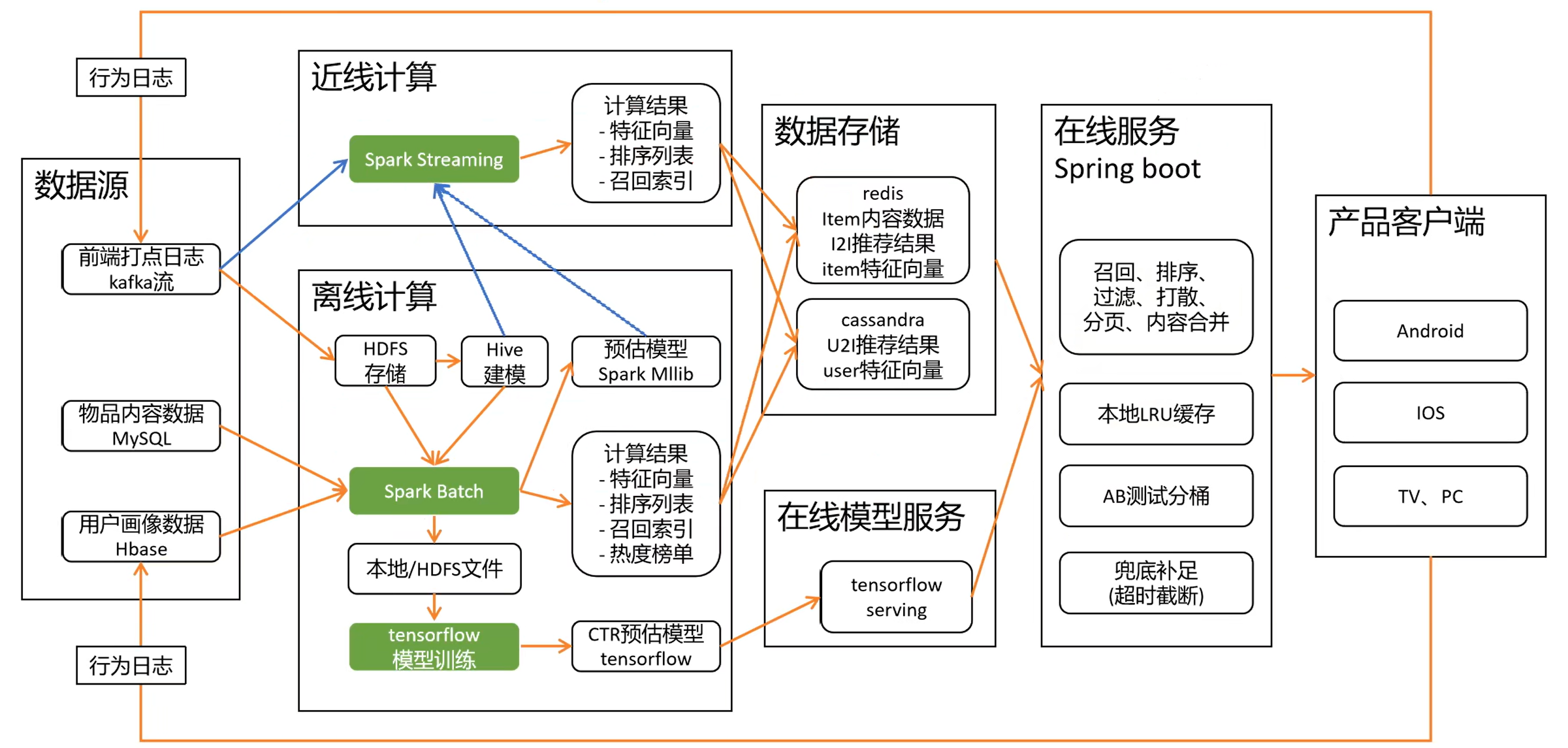
通用推荐系统技术架构(数据流图)
推荐系统的方法
Content-Based ; 基于内容的推荐系统
- 最早被使用的推荐算法,效果良好
- 给用户推荐之前喜欢的物品,相似的物品
- u2i2i
u2tag2i
重点:相似度计算
- 余弦相似度
优缺点
-
优点
- 不需要其他用户的数据
- 能给具备独特口味的用户推荐
- 可以推荐最新的、冷门的物品
- 容易做推荐结果的解释
-
缺点
- 很难找到能表达物品的“标签”,有时候需要人工打标签
- 过于局限于自己的世界,无法挖掘出用户的潜在兴趣
- 新用户如果没有行为,没法做推荐 (==冷启动问题==)
Collaborative-Filtering ; 协同过滤
-
大类,一般也分为两种
-
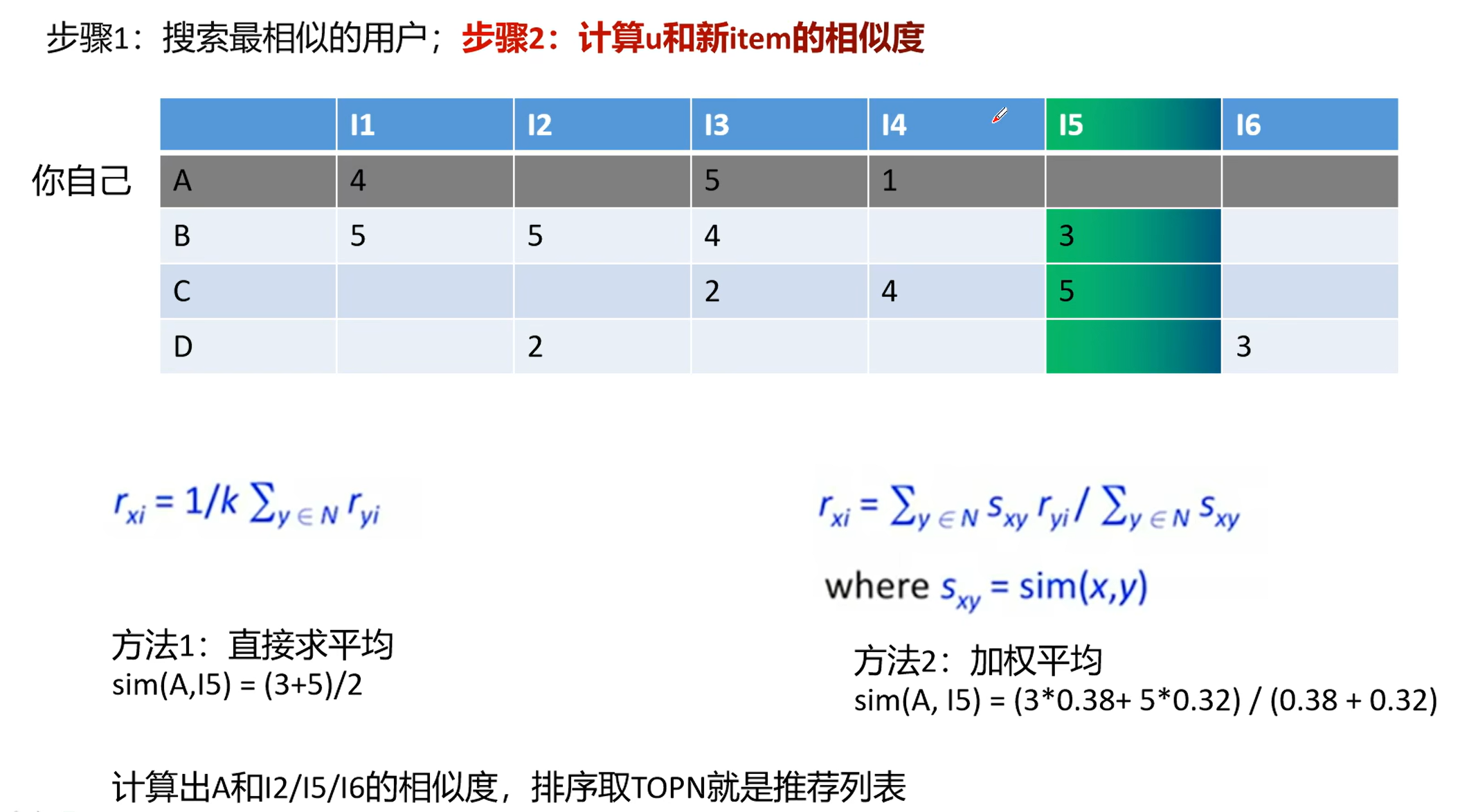
- Memory-based CF ; 基于数据统计(记忆)的协同过滤
- Model-based CF ; 基于模型(参数学习)的协同过滤
-
- 基于用户的协同过滤
u2u2i - 基于物品的协同过滤
u2i2i
- 基于用户的协同过滤
-
example
CF+Content-based ; 混合推荐系统
推荐系统一般问题
冷启动问题
实战应用考虑方法
多路召回融合排序
- 一般会使 用多个召回策略,互相弥补不足,效果更好,三个臭皮匠顶个诸葛亮。
- 每个策略之间毫不相关,一般可以编写并发多线程同时执行
- 问题:怎样将多个召回列表融合成一个有序列表?
举例,几种召回策略返回的列表(Item-ID、权重)分别为:
召回策略x:A0.9,B0.8,C0.7
召回策略Y:B0.6,C0.5,D0.4
召回策略Z∶C0.3,D0.2,E0.1策略:效果依次变好,按照成本进行选择
1、按顺序展示:比如实时>购买数据召回>播放数据召回,则直接展示A、B、C、D、E
2、平均法:分母为召回策略个数,分子为权重加和,C为(0.7+0.5+0.3)/3,B为(0.8+0.6)/3,
3、加权平均:比如三种策略自己指定权重为0…4、0.3、0.2,则B的权重为(0.40.8+0.60.3+O*0.2)/(0.4+0.3+0.2)
4、动态加权法:计算x/Y/z三种召回策略的CTR,作为每天更新的动态加权
5、机器学习权重法:逻辑回归LR分类模型预先离线算好各种召回的权重,然后做加权召回
推荐系统 AB Test
-
定义
- AB测试是一种向产品的不同受众展示同一内容的2个或多个变体,并比较哪个变体带来了更多转化的做法。
- AB测试是转化率优化过程的重要方法之一,使用它来收集定性和定量的用户见解,来了解潜在客户并根据该数据优化转化渠道。
-
必要性
- 想要数据驱动,重点是做AB对比实验,然后模型策略、设计等不断的迭代更新;
- 进行低风险的修改,先在小流量测试,如果没有问题再调大流量;
- 实现数据统计上的重大改进,降低人工猜测、直觉决策的不确定性;
- 怎样证明自己做的好?工程开发职位和算法职位的重大区分,后者更能用对比数据说话
AB Test基本架构
ab测试中常见问题
- 不要同时运行太多测试:
要确定测试的优先级,一起测试太多的元素很难确定哪个元素对测试的成功或失败影响最大。- 实验的流量大小:
流量样本的数量过小,实验结论不能使人信服- 测试持续时间不能太短:
运行测试时间过短会导致测试失败或产生不重要的结果- 无法遵循迭代过程:
A/B测试是一个迭代过程,每个测试都基于先前测试的结果,不管当前成功或失败,都不要停止继续AB测试
案例
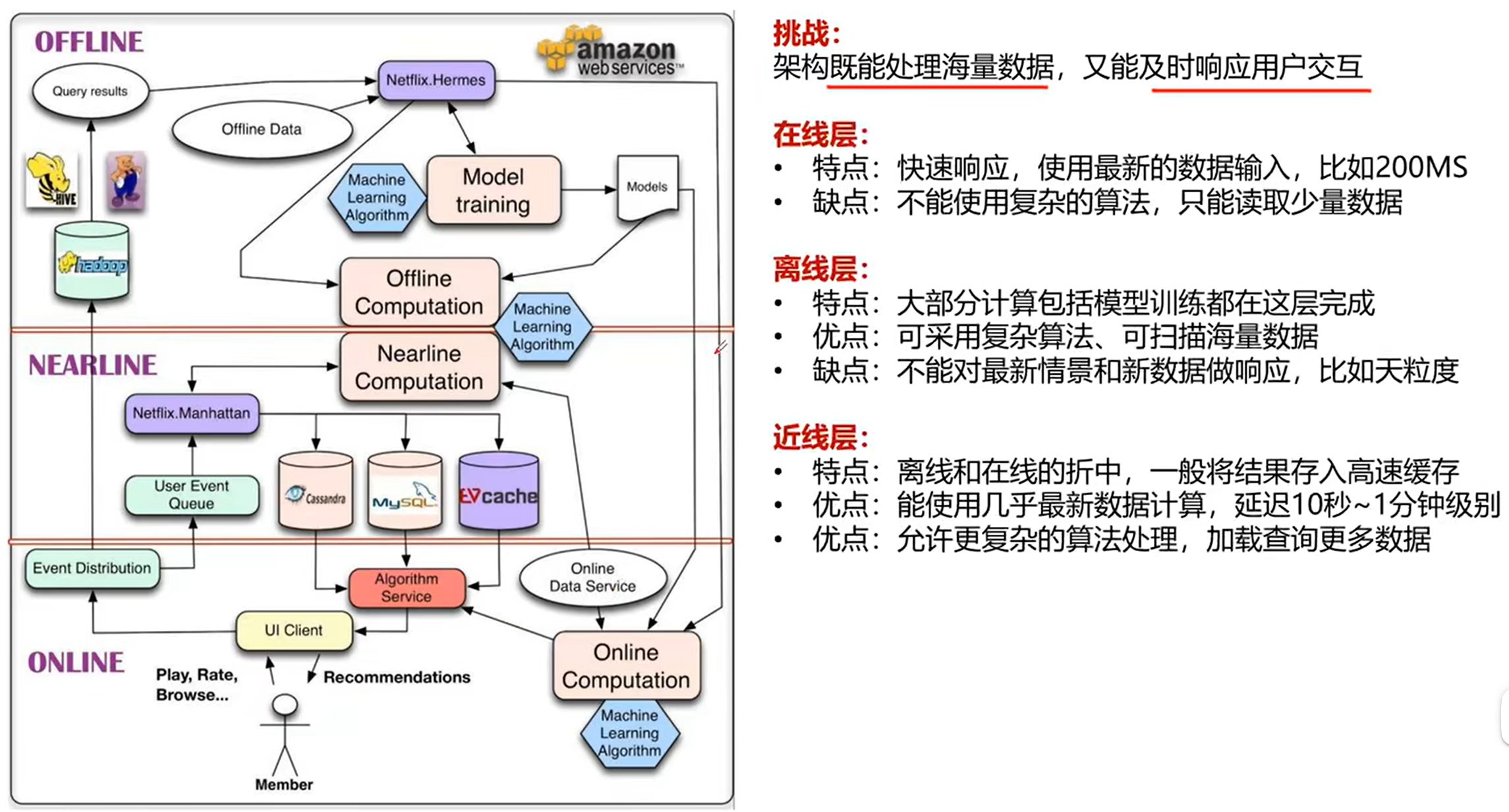
1. Netflix经典推荐系统架构
智能推荐系统未来展望
CCF C³活动第十八期:智能推荐与搜索,2023年3月30日周四(18:00-21:30),小红书北京举行
newbing ,AIGC, 大模型的冲击
- 对于网站盈利,网站存活的影响
- 对于广告商认定广告有效程度的认定
- 智能推荐可能的更大的发展
- 利用该大模型对于用户,心智捕捉更强的能力;能够真正做到智能推荐,给用户真正有用的推荐
- 生成式的大模型,需要关注使用场景
- 比如,风控领域,需要的是fact
- 适配大模型结合个人信息,个性化
- 存疑,未来推荐、搜索的形态
- 过去的搜索推荐,都是基于用户点击行为驱动的算法分发模式,走向用户
行为加内容理解,双轮并驱的内容分发模式 - 搜推一体化
在智能信息检索方面,如何发现并去除用户反馈中的偏差
-
因果分析
- 假设;因果图
总体是基于一种假设,没有对系统进行干预
搜推一体化不一定
但是搜索数据可以帮推荐,推荐的数据可以帮搜索
- 是否可以进行干预,自然干预的方法
- 不付出太多的代价,把搜索的query当成对推荐的一种干预
- 利用微观经济学中的一个概念,工具变量
- 稍微引入外部的知识进行干预,
- 是否干预,都是为了实现无偏估计
基于人类反馈的强化学习,LHF,对推荐有哪些启发
郝建业老师
传统强化学习的优化目标多是点击,时长
-
openai, 训练的三步,强化学习的面临的挑战
ss
-
如何进行强化学习梯度的训练
-
ctr预估,早已经利用了强化学习的思想《
当前推荐,有偏
强化学习 很难落地推荐
用户心智应该是一个序列决策问题
推荐领域的用户大模型,数据打通
数据质量
用户隐私,AIGC, --计算所,敖翔老师
菁蓉领域反欺诈领域
对抗性,其内的机理和范式是存在的
小红书,为什么脱颖而出 – 小红书技术负责人,夏侯
-
UGC社区而不是PGC社区
-
希望是一个去中心化的流量分发机制
-
交互和消费之间是怎样的trade-off,又是怎样建模
-
小红书内容的多样性
-
可行的流量货币化的机制
关于搜索
- 当前的搜索非常 中长尾,优化难度大
- 传统的搜索流量集中在头部
- chatgpt,
- 搜索,推荐互相finetuning
已有研究,把各类推荐任务统一到语言生成任务框架中,下一代推荐系统是否会形成大一统
大模型+插件,会不会形成新的OS,以后的app都变成插件
-
传统的搜索、推荐,是使用大量的用户数据,区训练模型,使得模型能够反映用户在使用这两种工具所自然的表现,喜好等等
-
而GPT的训练方式,还是使用了语言的特点
-
GPT 应用到搜索推荐的话,对应于搜索、推荐的行为做对齐
不同推荐场景的关联性有多大
大语言模型的开发和训练,需要极大的资源和算力
参考资料
 wechat
wechat alipay
alipay

